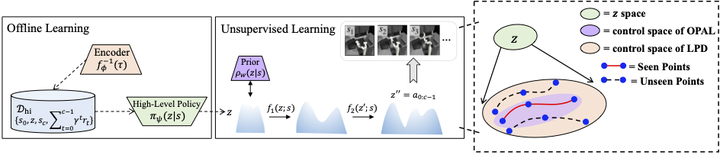
 Diagram of LPD
Diagram of LPD
Abstract
Offline reinforcement learning (RL) enables the agent to effectively learn from logged data, which significantly extends the applicability of RL algorithms in real-world scenarios where exploration can be expensive or unsafe. Previous works have shown that extracting primitive skills from the recurring and temporally extended structures in the logged data yields better learning. However, these methods suffer greatly when the primitives have limited representation ability to recover the original policy space, especially in offline settings. In this paper, we give a quantitative characterization of the performance of offline hierarchical learning and highlight the importance of learning lossless primitives. To this end, we propose to use a flow-based structure as the representation for low-level policies. This allows us to represent the behaviors in the dataset faithfully while keeping the expression ability to recover the whole policy space. We show that such lossless primitives can drastically improve the performance of hierarchical policies. The experimental results and extensive ablation studies on the standard D4RL benchmark show that our method has a good representation ability for policies and achieves superior performance in most tasks.